Abstract
Scope of Reproducibility
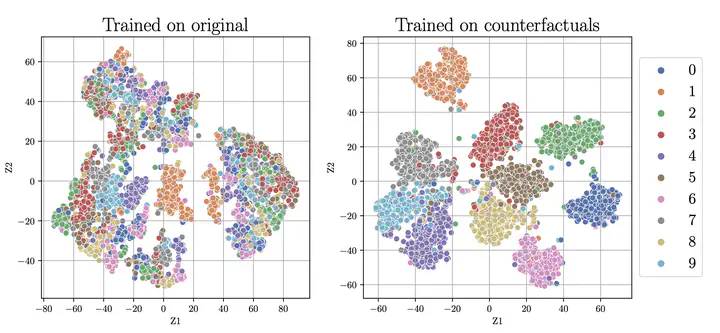
In this work, we study the reproducibility of the paper Counterfactual Generative Networks (CGN) by Sauer and Geiger to verify their main claims, which state that (i) their proposed model can reliably generate high-quality counterfactual images by disentangling the shape, texture and background of the image into independent mechanisms, (ii) each independent mechanism has to be considered, and jointly optimizing all of them end-to-end is needed for high-quality images, and (iii) despite being synthetic, these counterfactual images can improve out-of-distribution performance of classifiers by making them invariant to spurious signals.
Methodology
The authors of the paper provide the implementation of CGN training in PyTorch. However, they did not provide code for all experiments. Consequently, we re-implemented the code for most experiments, and run each experiment on 1080 Ti GPUs. Our reproducibility study comes at a total computational cost of 112 GPU hours.
Results
We find that the main claims of the paper of (i) generating high-quality counterfactuals, (ii) utilizing appropriate inductive biases, and (iii) using them to instil invariance in classifiers, do largely hold. However, we found certain experiments that were not directly reproducible due to either inconsistency between the paper and code, or incomplete specification of the necessary hyperparameters. Further, we were unable to reproduce a subset of experiments on a large-scale dataset due to resource constraints, for which we compensate by performing those on a smaller version of the same dataset with our results supporting the general performance trend.
What was easy
The original paper provides an extensive appendix with implementation details and hyperparameters. Beyond that, the original code implementation was publicly accessible and well structured. As such, getting started with the experiments proved to be quite straightforward. The implementation included configuration files, download scripts for the pretrained weights and datasets, and clear instructions on how to get started with the framework.
What was difficult
Some of the experiments required severe modifications to the provided code. Additionally, some details required for the implementation are not specified in the paper or inconsistent with the specifications in the code. Lastly, in evaluating out-of-distribution robustness, getting the baseline model to work and obtaining numbers similar to those reported in the respective papers was challenging, partly due to baseline model inconsistencies within the literature.
Communication with original authors
We have reached out to the original authors to get clarifications regarding the setup of some of the experiments, but unfortunately, we received a late response and only a subset of our questions was answered.